Comparing images from two folders
• • Reading time: 5 minutes
Last updated:
Sometimes psychology researchers need to recycle stimuli from old experiments, usually because they have already got some standardized measures for the old stimuli.
Say for my new experiment, I want to recycle visual stimuli from both Exp A and Exp B. But here’s the problem: some of the stimuli from the two experiments are duplicates, and the duplicates all have different file names. How do I make sure I don’t have duplicates in the recycled stimuli?
On this page, I share a Python script that compares images from two folders and removes duplicates.
Step 1: Preparation
Download the Python script.
Gather your images to compare in two folders.
This script will compare every image in folder 1 with those in folder 2 and vice versa to search for duplicates, but it will not try to find duplicates within each folder. It’s built this way with in mind the process of recycling visual stimuli from old experiments, thus folder 1 may be a folder where visual stimuli from Exp A are saved, and folder 2 is for Exp B. Within one experiment I assume the researcher has already checked for duplicates when they did the experiments previously.
Step 2: Run the script
Open compare_images.py in an IDLE.
This script will take every image in folder 1, compare it with every image in folder 2, and vice versa. A summary file summary.csv will be created, which is a list of unique images from the two folders. This script can optionally copy all unique images to another folder, with duplicates renamed. In case of a duplicate, the script will write down the image’s file name in folder 1 and folder 2 respectively, and its new name if copy == True.
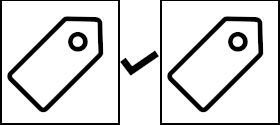
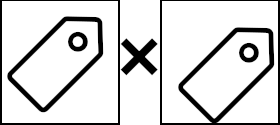
Note that this script uses the imagehash package to compare images. This package is good at detecting true duplicates, but cannot detect slightly edited images:
At the beginning of the script, define your variables:
dir1(string) is the first folder to compare.dir2(string) is the second folder to compare.format(list of strings) is a list of all image formats to compare.outdir(string) is the directory to save the summary file.copy(boolean) controls whether the script copies unique images to a new folder.copydir(string) the directory to copy unique images to, ifcopy = True.
Run the script, and a summary.csv will be created, like this:
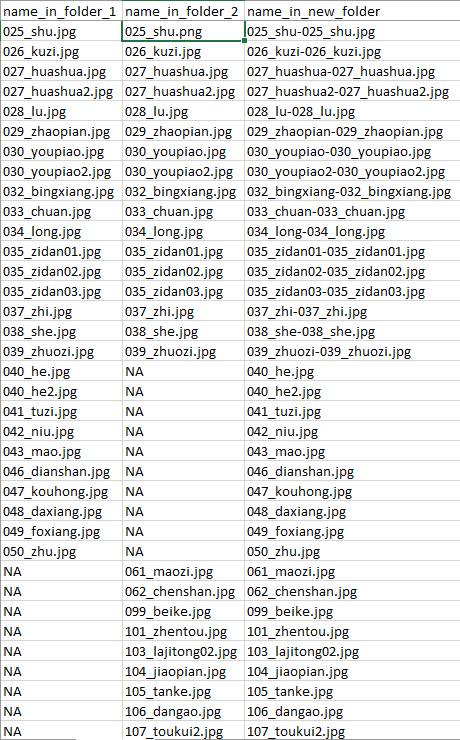
Images will also be copied if copy == True. Note that as the images are duplicates, the script will copy the image from folder 1 to the new folder.
If copy == False, the summary file will look like this: