Automated processing of Chinese cloze responses
• • Reading time: 4 minutes
Last updated:
The cloze task is widely used in psycholinguistics, mainly to determine the predictability of a word given certain context. In a cloze task, the participant sees incomplete sentences, and is asked to complete the sentences by writing down one or a few words. The predictability, or the cloze probability, of a given word is the proportion of people who fill a gap in a sentence with that specific word. Therefore, processing cloze responses includes counting the frequency of each word appeared in all responses. In many languages, such as English, this task is easy to automate: word boundaries are easy to determine. In languages such as Chinese, where no written word boundaries exist, we need a solution to automate the processing of cloze responses.
One possible solution is to use a text segmentation tool. Many good text segmentation tools exist for Chinese for python, such as Jieba, SnowNLP, PkuSeg. However, I find that text segmentation is not necessary for processing cloze responses. Instead, I present a solution based on a Chinese word database, SUBTLEX-CH.
SUBTLEX-CH is a database of word frequencies based on a corpus of film and television subtitles (33.5 million words). I chose to process my cloze data based on this database because it includes most Chinese words, and its format is fairly easy to process.
I have created two scripts to extract the frequency of every noun (including common nouns and proper nouns) appeared in responses. The scripts only count nouns as nouns are the most common target words in psycholinguistics experiments using eye-tracking or ERP methods. You can modify the script to accommodate the parts of speech you would like to include in your results.
On this page, I will explain step-by-step how my scripts work.
On this page
- Step 1: Preparation
- Step 2: Create a word index using SUBTLEX-CH
- Step 3: Process cloze responses
- Step 4: Manually integret sub- and super-category responses
Step 1: Preparation
Go to SUBTLEX-CH and download SUBTLEX-CH-WF-PoS.zip. Extract SUBTLEX-CH-WF_PoS.xlsx.
Find the python scripts and some sample data here.
Pre-process your data. Your data should be in long form (one response per row), in .csv format, and contain at least these two columns:
- sentence: your sentence frames
- response: your participant’s response
sample_data.csv provides some sample data.
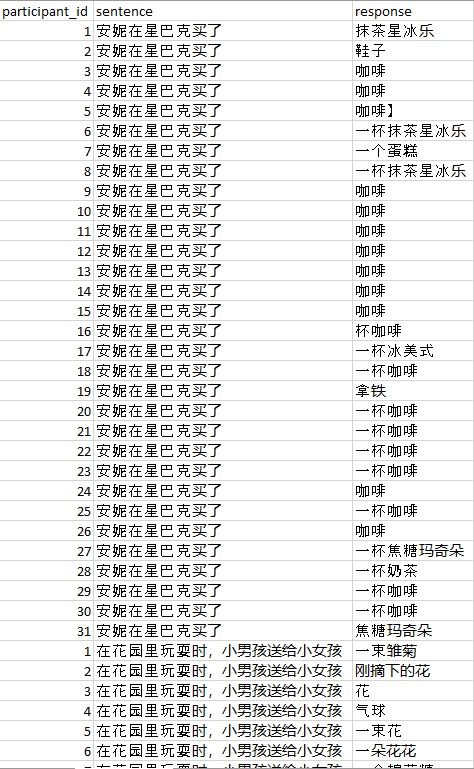
Finally, put your data.csv, SUBTLEX-CH-WF_PoS.xlsx, 01_create_index_using_SUBTLEX_CH_PoS.py, and 02_process_cloze_data.py in the same folder.
Step 2: Create a word index using SUBTLEX-CH
Run 01_create_index_using_SUBTLEX_CH_PoS.py. Required modules: os, openpyxl, csv
This should create index.csv in the index folder.
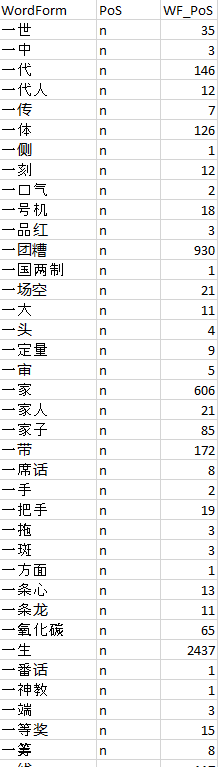
If you would like to process not only nouns, you can modify line 21 to include all parts of speech you would like to include. A list of part of speech coding used in the database can be found here.
21 pos = ['n', 'ng', 'nr', 'ns', 'nt', 'nx', 'nz']
For example, if you want both nouns and adjectives:
21 pos = ['n', 'ng', 'nr', 'ns', 'nt', 'nx', 'nz', 'a']
Step 3: Process cloze responses
Open 02_process_cloze_data.py.
This script will first sort the index from longest to shortest, and count each appearances of the longest possible word(s) in each response. For example, if the participant responded with “北京烤鸭”, “北京” and “烤鸭” will be counted once respectively, while “北” or “鸭” will not be counted. This avoids multiple counting.
Check lines 23 to 32 for the variables, customise if needed:
23 # settings
24 inputFile = 'data.csv'
25 outputFile = 'cloze_results.csv'
26 responseColumn = 'response' # the column name of responses
27 sentenceColumn = 'sentence' # column name of sentence frame
28
29 inputFormat = 'utf-8' # input format. Default utf-8
30 outputFormat = 'utf-8-sig' # output format. Default outputs a utf-8 csv file with BOM to read easily in MS Excel
31
32 header = ['sentence', 'response', 'count', 'cloze_probability', 'number_of_response'] # header of the output file
Run 02_process_cloze_data.py.
An output file should be created in the same folder.
The output csv file contains five columns:
- sentence: your sentence frame
- response: the word being counted
- count: number of times the word appeared in all responses
- cloze_probability: count / number_of_response
- number_of_response: number of people who provided a response to this sentence
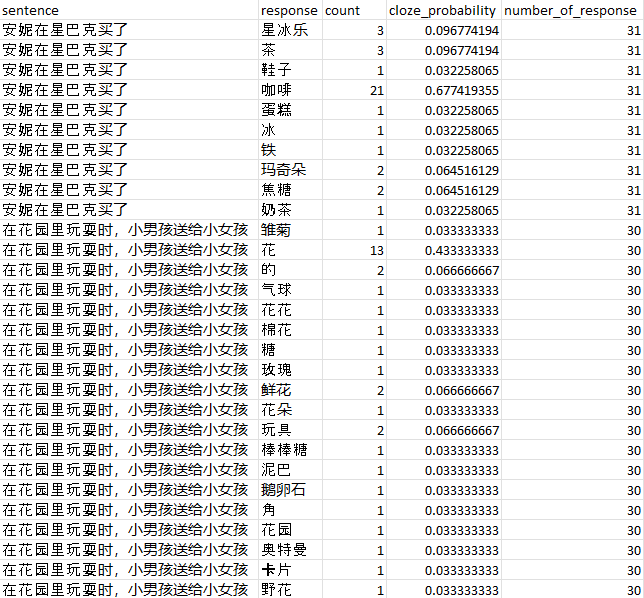
If the participant did not respond with a noun (or any of the parts of speech you are interested in), the script will count no_match once, and this entry of response will still be added to the total number_of_response. If your frequency of no_match is too high for a sentence, it’s probable that SUBTLEX-CH did not have your target word. Simply add your target word to the index to solve this. You can either modify the scripts, or simply modify index.csv.
Step 4: Manually integret sub- and super-category responses
After the processing, you will need to manually integret sub- and super-category responses. For example, in the sample output, for sentence two, you may consider adding the frequency of 雏菊, 玫瑰, 鲜花, 花朵, 野花 etc. to the frequency of 花.
References
Cai, Q., & Brysbaert, M. (2010). SUBTLEX-CH: Chinese Word and Character Frequencies Based on Film Subtitles. Plos ONE, 5(6), e10729. https://doi.org/10.1371/journal.pone.0010729.