Make auditory serial presentation stimuli
• • Reading time: 4 minutes
Last updated:
Psycholinguistic research sometimes requires the stimuli to have specific timing. On this page, I share a Praat script that given the stimulus-onset asynchrony (SOA), makes auditory serial presentation stimuli from continuous speech recordings and their textgrids.
Step 1: Preparation
Download the Praat script.
Gather your stimuli .wav files, and make your .Textgrid files. The .Textgrid files should have the same name as your .wav files. Your textgrid files should contain at least one interval tier that Praat will use to make the serial presentation stimuli. For example, if I want to present a sentence word-by-word, with a between-word SOA = 800ms, my textgrid should look like this, where:
- Each word should be a named interval.
- Each interval name should be used only once. (Thus I numbered all my intervals.)
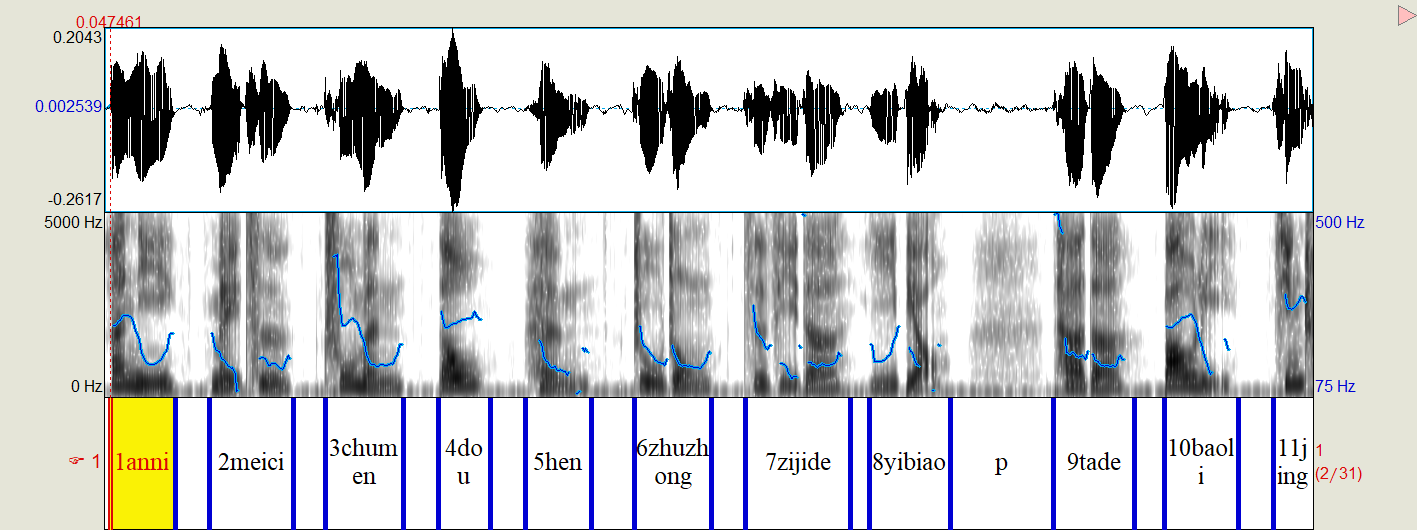
Additionally, since this script is originally designed to make sentence stimuli, it allows the user to define punctuations. Punctuations will be added as additional silences in the final product. All punctuations should have the same interval name, here I used ‘p’.
Note that while recording this example, the speaker was instructed to speak one word at a time, to avoid co-articulation. This script will of course be able to handle completely natural recordings, provided the correct textgrid annotations.
Step 2: Run the script
Download and run Praat.
Select Praat - Open Praat script…, and select auditory-SP-stimuli-from-textgrid.
If on Mac OS, replace the “" in line 44 with “/”.
Select Run - Run. You will be presented with a user interface, where you can specify a number of variables.
- The generals:
- file directory: Where your
.wavand.Textgridfiles are located. Do not put\at the end. - save directory: Where you want your output files to be saved. Do not put
\at the end. - txt file name: Aside from manipulating the
.wavfiles, the script will also generate a.txtfile in the end which indicates the onset and offset of each interval in the final product. Define the.txtfile’s name here. - new sound file name ending: You can optionally rename your output
.wavfiles. For example, if you say_sphere, your01.wavwill output01_sp.wav. Leave blank if you do not want to rename the output files.
- file directory: Where your
- The specifics:
- critical tier number: The index of the interval tier that Praat will use to process the recordings.
- soa in seconds: Your stimulus-onset asynchrony (SOA). In seconds.
- stretch fragments: If checked, Praat will stretch fragments that are shorter than your SOA to the length of your SOA, so that stimuli can be perceived as continuous.
- allow overtime: If unchecked, Praat will compress fragments that are longer than your SOA. If checked, Praat will not compress long fragments (note that this will not preserve the SOA).
-
minimum silence duration seconds: You can optionally define a minimum duration of silence, if you wish to make sure each fragment is separated by at least some silence.
If
allow overtimeis unchecked, Praat will compress long fragments such that SOA is preserved after minimum silence is added to the end of the fragment. Ifallow overtimeis unchecked, Praat will simply attach the minimum silence to the end of the fragment (note that this will not preserve the SOA).If
stretch fragmentsis checked, Praat will stretch short fragments such that the duration of stretched fragments + minimum silence = SOA. - punctuation name: The name of your punctuation interval. Note that this entry cannot be left blank. If you do not have punctuation in your stimuli, put at least one character here that is not the full name of any of your intervals.
- punctuation duration: The duration of punctuation. In seconds.
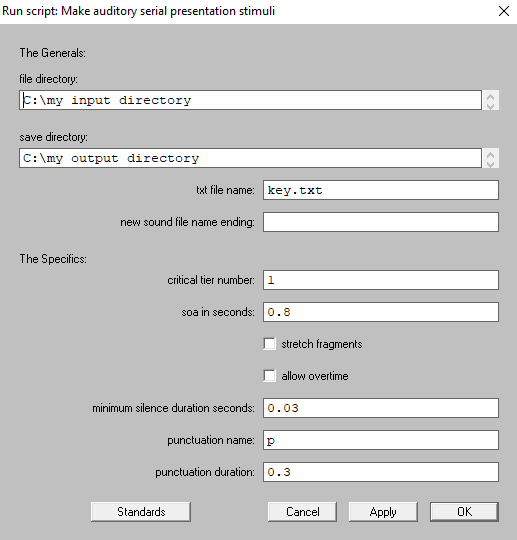
Define the variables based on what you need, then select OK. Praat will start processing your .wav files.
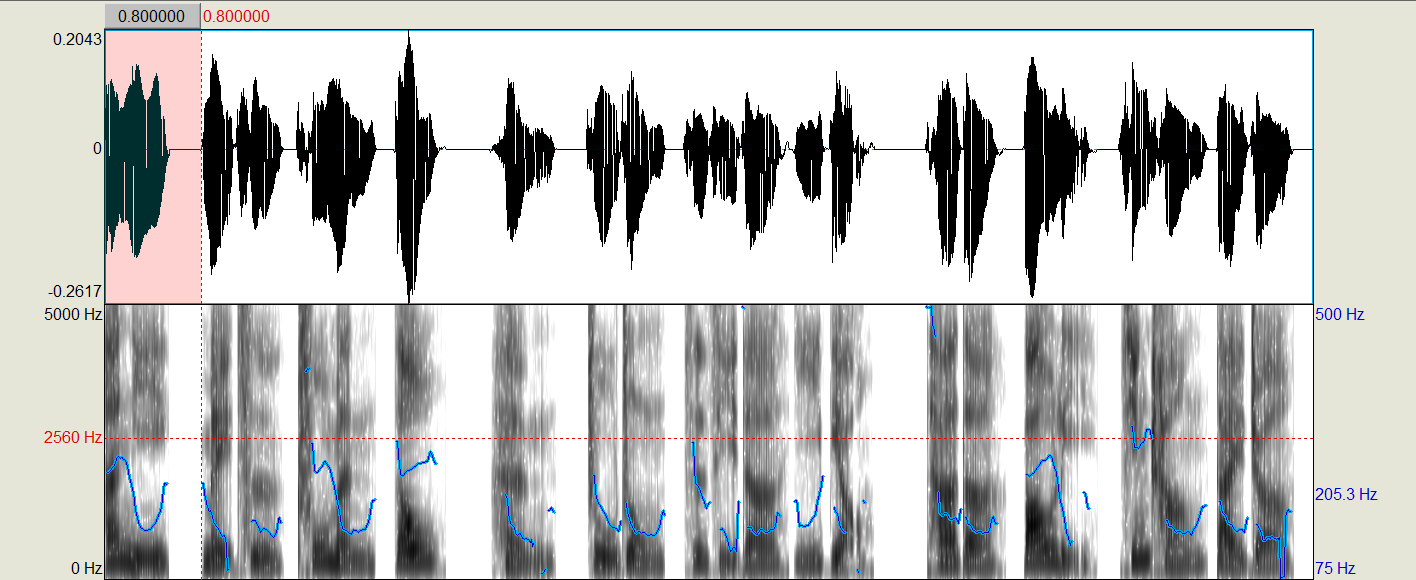
An example output .wav will look like this in Praat:
In addition, Praat will also write a .txt file to summarise the onset and offset of each fragment (including the silence):
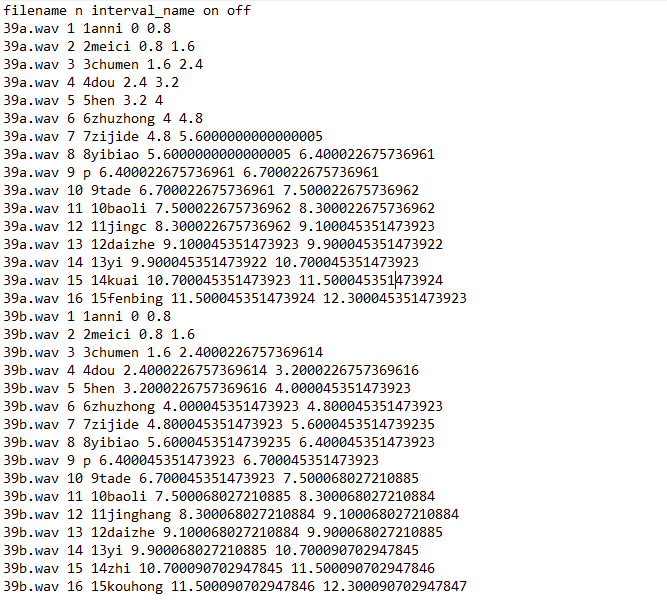
You can see that Praat isn’t perfect at manipulating the durations, but on the millisecond level, it does a good enough job.